Concepts
After this tutorial, you will be able to:
- Understand L2MAC's concept of a prompt program and how it works
- How it uses memory to store the intermediate outputs from completing each step instruction in the prompt program, and re-use this growing memory for subsequent step instructions
The goal is to provide an intuitive and simplified explanation of the concepts so that users have a background to further explore the tutorial series. While we aim for clarity, we also recognize simplifications can produce inaccuracy or omission. Therefore, we encourage more navigation over subsequent documents for complete comprehension.
You may also jump to L2MAC 101 if you want hands-on coding first.
Check out our ICLR 2024 paper for a complete, rigorous explanation.
High-Level Overview
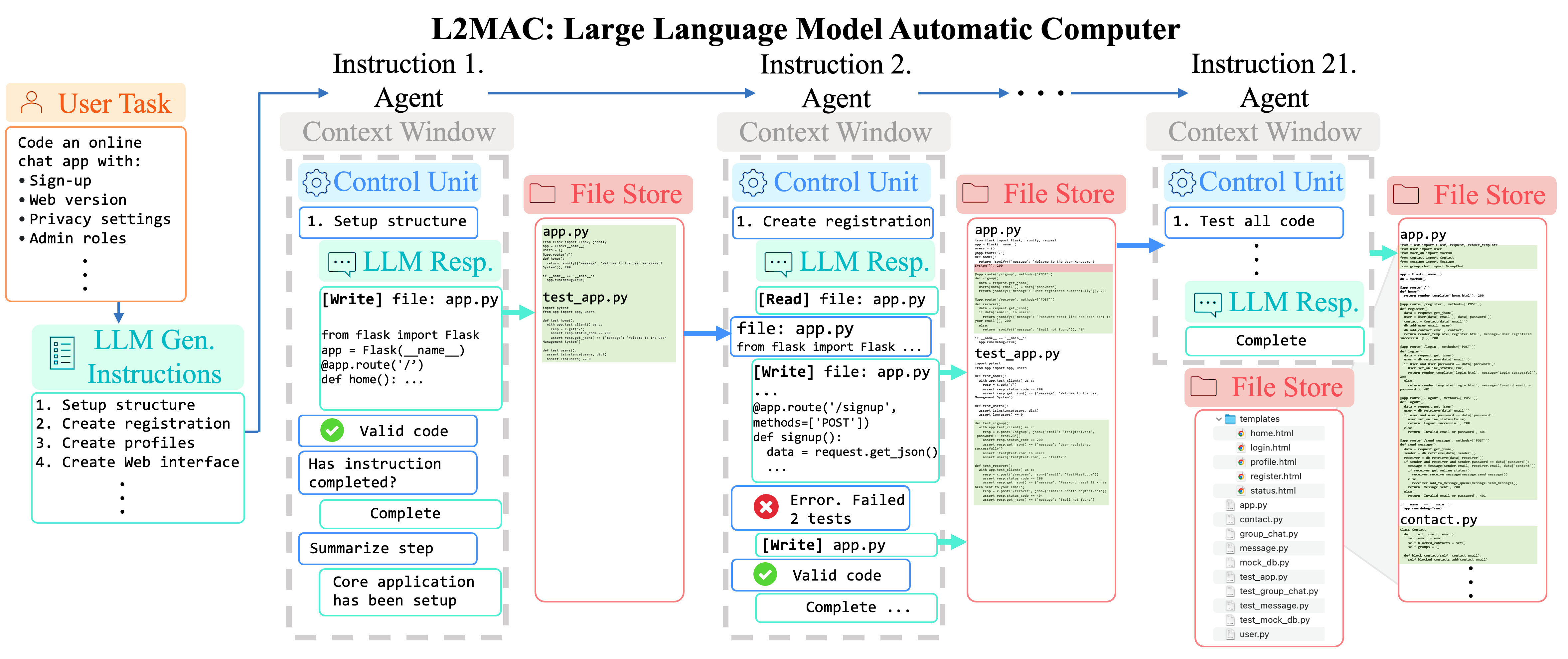
L2MAC Overview. Here the LLM-automatic Computer Framework is instantiated for extensive code generation tasks. First, it takes in a single user input prompt, for example, "Create an online chat app...", and the underlying LLM understands the user task and breaks it down into sequential instructions, a prompt program to execute to complete the task. We note that self-generating a prompt program is a form of bootstrapping, and L2MAC also supports being given the prompt program explicitly as input. Mirroring the operation of a computer, each instruction of the prompt program is sequentially loaded into a new instance of an LLM agent, where we make the LLM an agent by providing it with tools and the ability to perform actions sequentially.
The Control Unit (CU) manages the LLM agent's context window for each instruction (agent) and empowers the LLM agent to interact with an external memory file store through read, write, and evaluate tools. Crucially, this external memory file store stores the prompt program, as well as the intermediate and final outputs of the execution of following the prompt program to solve the given task; this follows the stored-program computer, or von Neumann architecture approach of storing both the program and the program output in memory. It identifies and reads relevant files from the memory to generate or update files per instruction. This ensures proper conditioning of existing files without losing vital context. Automatic checks evaluate the LLM's outputs for correctness and completion, with iterative error corrections involving both code syntactical checks of the code and running self-generated unit tests to check desired functionality. Overall, this produces a complete large codebase that fulfills the detailed user task in the file store.
Benefits of the LLM-automatic Computer
By using the LLM-automatic computer framework, we gain the immediate strong benefits of:
- Strong empirical performance beating existing LLMs and other leading LLM multi-agent and LLM compound AI frameworks for codebase generation tasks, and single coding tasks, such as HumanEval..
- Can augment any existing LLM with the ability to follow a near-infinite length and complex prompt program to solve a given task.
- Can generate a near-infinite amount of output for a given task when following a prompt program.
- Can generate intermediate outputs, either from thinking and solving parts of the difficult task already or from the use of tools, and re-use these intermediate thoughts at later stages of its operation to solve more complex and difficult tasks that require many LLM thinking steps to solve, for example, generating an entire codebase for a complex application, refires conditioning, understanding and potentially modifying many of the previously generated code files in the code base.
- By creating and following a prompt program, we can create large unbounded outputs that align exactly with what the user desires rather than autonomously think and forget what the original user input requirements were, which is the case of AutoGPT (page 8).
- By breaking a large task into a sequential prompt program, we can generate the final output as one part at a time, enabling LLMs with fixed context windows to generate significant unbounded outputs that are significantly greater than their underlying context window. We note that this also helps large context LLM models, as prior work has shown that even when using a large context LLM model, their attention is largely restricted to the most recent small percentage of the context window.
- Mirroring the development of the computer, we believe that the advancement of the LLM-automatic Computer Framework enables a general-purpose task-solving framework, where it can solve any task by simply re-programming the prompt program, whereas many existing multi-agent systems today, specialize for only one task, which is reminisnicnt of the first computing machines, where the breakthrough was a re-programmable automatic or Universal automatic computing machine.
Low-Level details
All transformer-based LLMs have a fixed context window, limiting the number of tokens and characters they can process. Therefore, this restricts a single LLM from generating any larger output than its fixed context window constraint, such as a large codebase or entire books. A natural solution is to extend an LLM agent with external memory. However, existing methods use too simplistic memory stores, such as an external corpus of previous summarizations, which is append-only or maintains precise values for variables with databases or a dictionary without any provision for in-place updates. Compounding this, the existing works do not include mechanisms for maintaining syntactic or semantic consistency within the memory store, a vital requirement for the generation of coherent and interdependent large code structures.
Considering these issues, we introduce the LLM-automatic computer (L2MAC) framework, which is the first practical LLM-based general-purpose stored-program automatic computer (von Neumann architecture) framework, an LLM-based multi-agent system for long and consistent output generation. Here we mean automatic in the sense that it can automatically follow the internal prompt program without human intervention, mirroring early computers, such as Turing's (Automatic-)machine (page 17).
A Control Unit (CU) orchestrates the execution of the individual LLM agents and their interaction with the memory store. As outlined in the above Figure, an LLM agent first generates a task-oriented prompt program from a detailed user-specified task. The CU tailors the LLM agent's context, so it always includes the next unresolved instruction in the prompt program and information about the execution of past iterations (agents), and declutters the context when approaching its limit. It also endows the LLM agent with the ability to read and update any existing region of the memory store or extend it with new outputs. Furthermore, the CU plays a crucial role in checking the generated output. It feeds the LLM agent with syntactical checker errors and requests the LLM agent to generate checks alongside generating output, here unit tests when generating code, which are verified at each update of the memory file store to trigger corrective actions if needed, thereby ensuring that the extensive output in memory is both syntactically and functionally consistent.
L2MAC Framework
Now we outline the L2MAC framework for the first practical LLM-based stored-program computer, with an instantiation for coding illustrated in the above Figure. L2MAC consists of three main components: the LLM processor, the memory file store, and the Control Unit (CU) that controls the flow of the execution, thus endowing the LLM agent with read-and-write capabilities, among other capacities---this is illustrated in the below Figure.
LLM-based Processor
An LLM can be viewed as a more complex atomic unit of computation with a fixed context window input; this allows for a flexible and powerful computation unit that can be used to solve a range of different tasks. Additionally, the LLM is empowered with tools forming an LLM agent, where it can select which action to execute next or provide an output. Critically, the LLM produces a probabilistic output; it is regarded as a hallucination when it makes an erroneous output. Thus, crucial to effectively updating an interrelated memory is the ability to enforce periodic checks on the LLM output to ensure correctness and consistency.
Memory
Following a stored-program computer, we define two types of memory: that of the prompt program (or instructions) and that of the file store. Here, the file store stores information relevant for the processor to read, write, and evaluate, with the final output ultimately stored in the file store.
Control Unit
The control unit is responsible for managing the context window for the LLM, encompassing both its inputs and outputs, executing the LLM, checking its outputs for errors, and enabling it to call tools (functions), which include reading and writing to the memory file store. We provide the following figure to detail its operation.
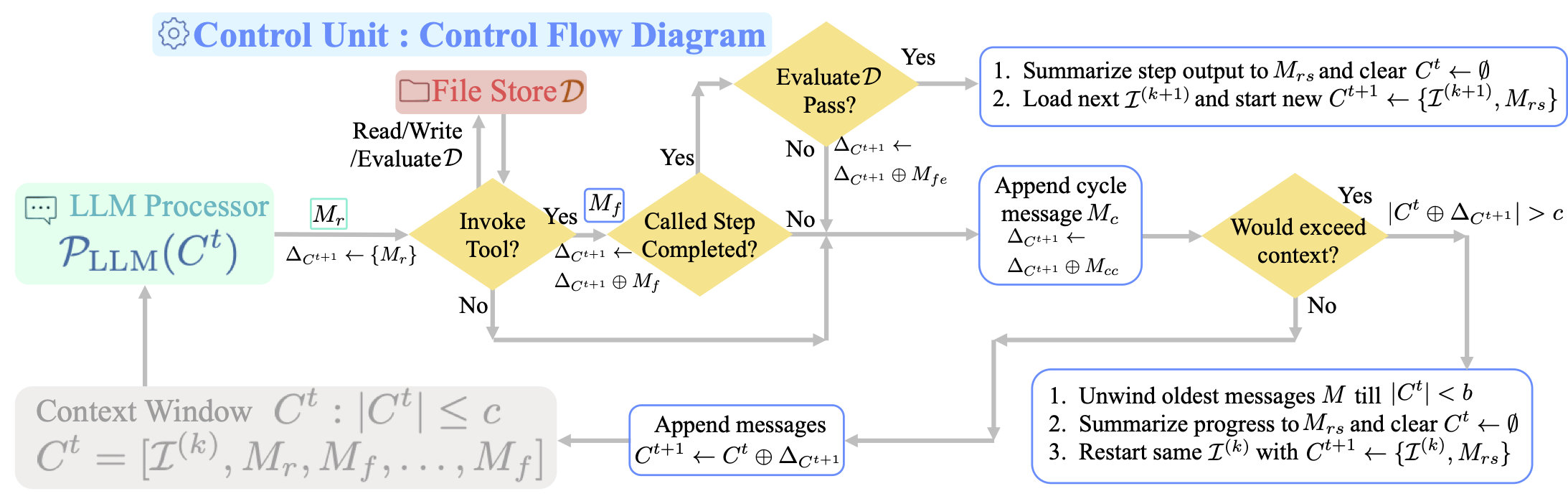 Control Unit-Control flow diagram for one dialog turn
Control Unit-Control flow diagram for one dialog turn
Task-Oriented Context Management
The Control Unit (CU) uses the LLM as a multi-turn dialog system, filling its context window
To make L2MAC an automatic computer, the CU prompts the LLM to fill the initially empty instruction registry
Overcoming the fixed context window constraint. The input to the LLM cannot exceed the context window constraint
Regarding (1), through appropriate crafting
Precise Read/Write tools for entire memory
The need for a reading mechanism that retrieves the relevant information at each iteration is evident and has been reasonably explored in previous literature. In contrast, previous work on memory has paid little attention to the writing component, which gets mostly reduced to the appending of new prompts and LLM outputs or updating the values of very structured and thus restrictive forms of memory, e.g., variables or tables.
These approaches make sense for summarization, dialogs, and database manipulation tasks but are not suitable for long interconnected output generation tasks, such as generating large codebases for system design tasks. Indeed, in such settings, the possibility of downstream subtasks
In L2MAC it is thus key to implement read/write interactions with any part of the memory. We want the agent to be able to scan on demand
Checking the generated output
As discussed in LLM-based Processor above, the intrinsic stochasticity of LLMs and the well-known phenomenon of hallucination makes it likely that incoherent or erroneous outputs occur during long interactions, which can be disastrous, for example, in coding. More profoundly, changes (e.g., to a function) to satisfy a given instruction
Error checking and error correction. Using a given evaluator module
Checking for current instruction completion. To ensure continued execution in a multi-turn dialogue LLM system until completion, we request the LLM to decide on the next step to take, which can involve executing a tool. This is achieved through a cycle prompt message
L2MAC for Coding Tasks
Now, we use our LLM-automatic computer (L2MAC) framework and instantiate it to complete large codebase generation tasks. We distinguish the general-purpose task long-generation framework from the code instantiation to detach the core components from task domain decisions that can be appropriately adapted to other task domains. We provide the full details of the implementation in the paper page 19; yet here we highlight some notable design decisions on the memory layout (in particular,
We specify the memory file store models/user.py suggests that it contains the data model for the user class. This choice is not only valuable for a human reader but also crucial for our Read-and-Write implementation, as it allows the LLM to infer the content of existing files
Now, you have a first glance at the concepts. Feel free to proceed to the next step and see how L2MAC provides a framework for you to create extensive outputs.