How does L2MAC compare against AutoGPT, GPT-4 and existing methods?
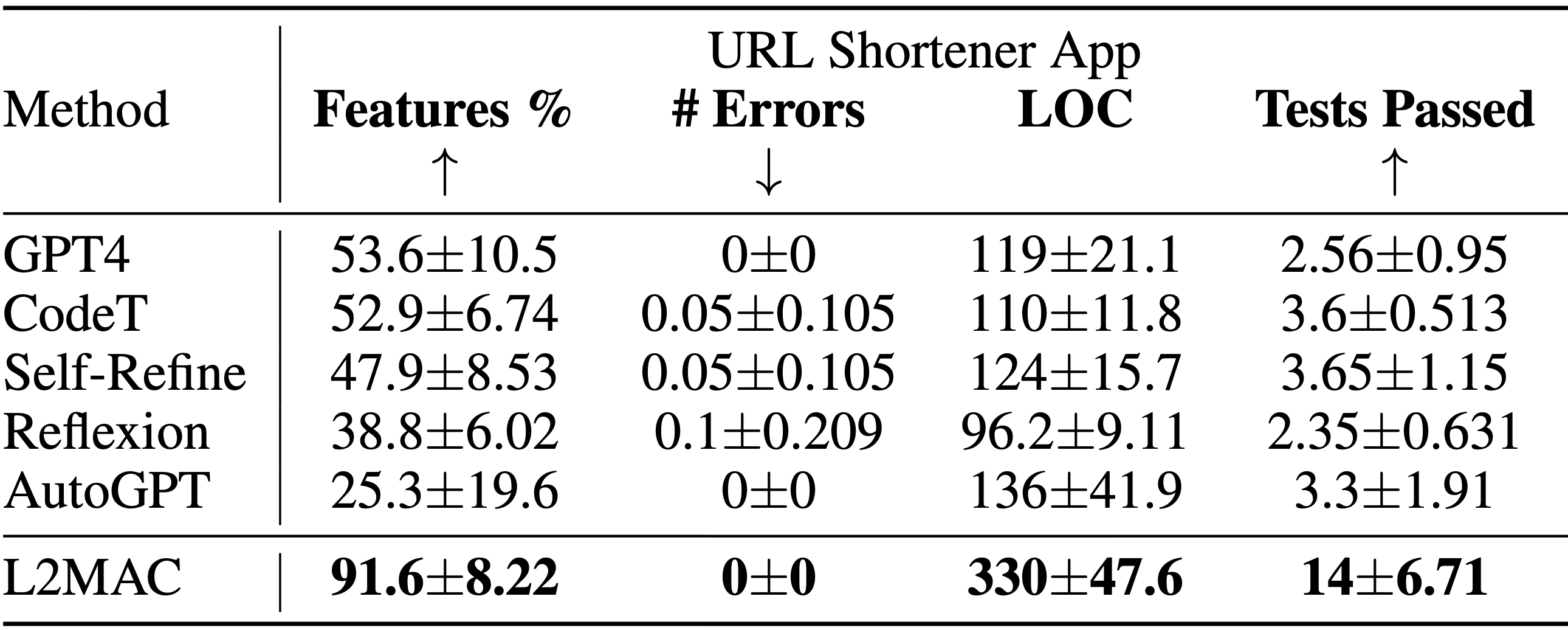
LLM-Automatic Computer (L2MAC) instantiation for coding a large complex codebase for an entire application based on a single user prompt. Codebase generation system design task results showing the percentage of functional features specified that are fully implemented (Features %), the number of syntactical errors in the generated code (# Errors), the number of lines of code (LOC), and the number of passing tests (Tests Passed). L2MAC fully implements the highest percentage of user-specified task feature requirements across all tasks by generating fully functional code that has minimal syntactical errors and a high number of passing self-generated unit tests, therefore it is state-of-the-art for the generation of large output codebases, and similarly competitive for the generation of large output tasks. The results are averaged over 10 random seeds.
- L2MAC fully implements the highest percentage of user-specified task feature requirements across all system design tasks in the paper (with one being shown above) by generating fully functional code that has minimal syntactical errors and a high number of passing self-generated unit tests—therefore, L2MAC is state-of-the-art for completing these system design large codebase generation benchmark tasks..
- We further evaluated L2MAC on the standard HumanEval benchmark and observe that it achieves a state-of-the-art score of 90.2% Pass@1.
- L2MAC also works for general-purpose extensive text-based tasks, such as writing an entire book from a single prompt.
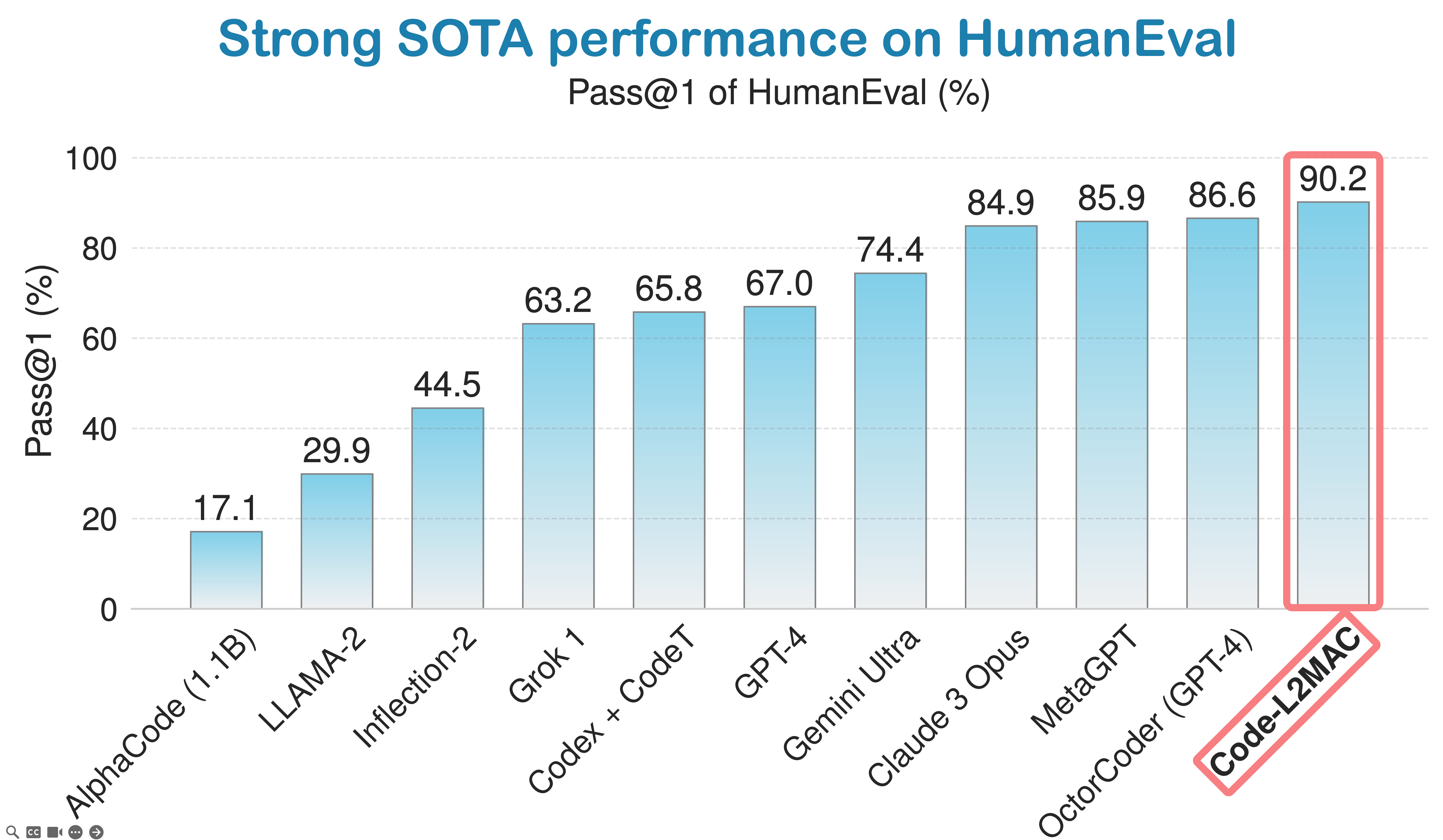
LLM-Automatic Computer (L2MAC) achieves strong performance on HumanEval coding benchmark and is currently ranked the 3rd best AI coding agent in the world on the global coding industry-standard leaderboard of HumanEval.
In depth-comparison to AutoGPT and GPT-4
Can L2MAC correctly perform task-oriented context management?
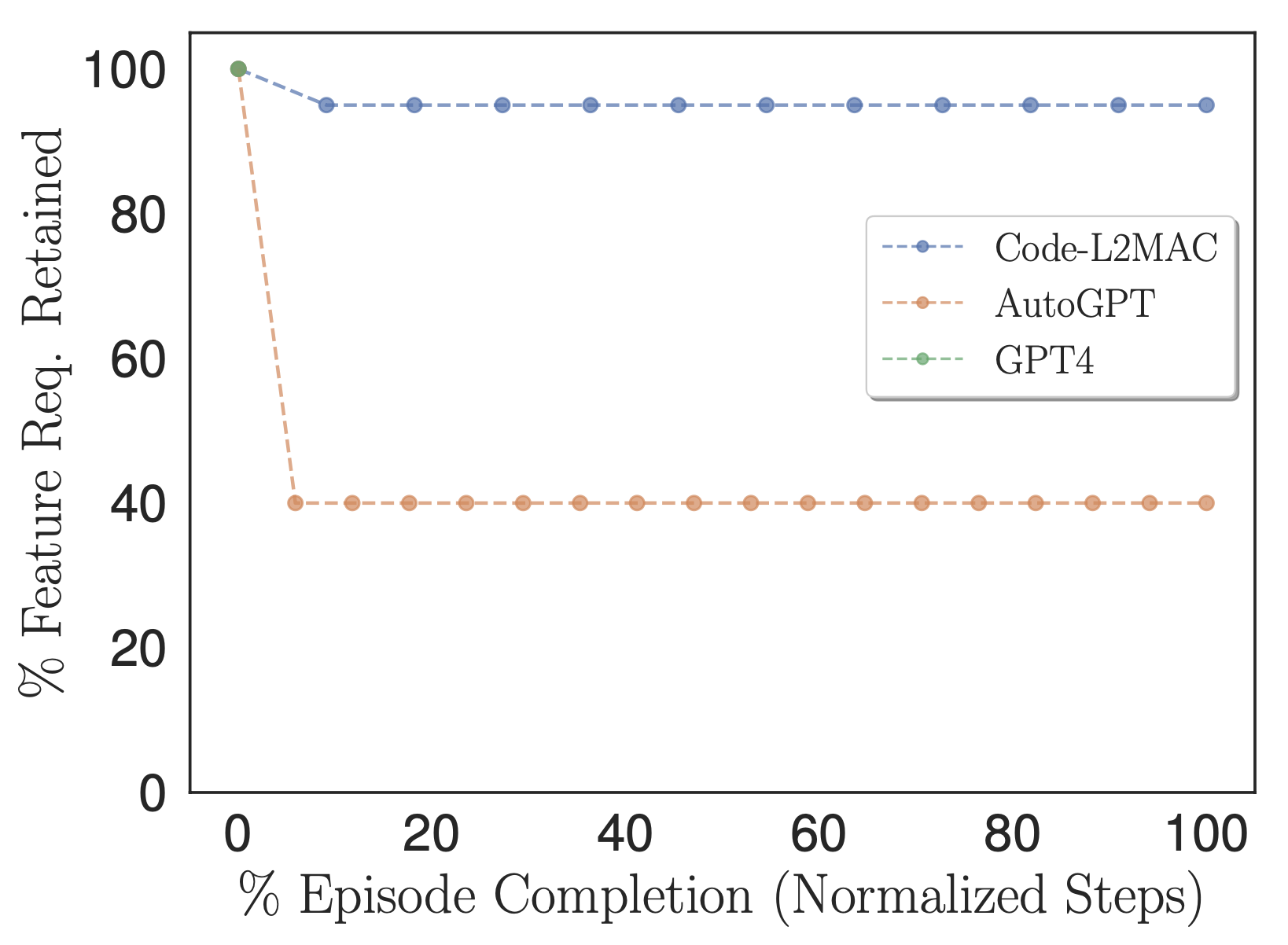
Percentage of user-specified feature requirements that are retained within the methods task instructions and used in context.
To explore if the benchmarked methods during operation contain the information within their context to complete the task directly, we adapted our Features % metric to count the number of user-specified task feature requirements that are retained within the methods task instructions instead, i.e., those instructions that are eventually fed into its context window during its operation, as shown in the above figure. Empirically, we observe that L2MAC is able to retain a high number of user-specified task feature requirements within its prompt program and perform instruction-oriented long-running tasks. We note that AutoGPT also initially translates the user-specified task feature requirements into task instructions; however, it does so with higher compression—condensing the information into a mere six-sentence description. This process results in the loss of crucial task information necessary for completing the overall task correctly, such that it aligns with the detailed user-specified task.
Can Code-L2MAC perform precise read/write operations for the entire file store?
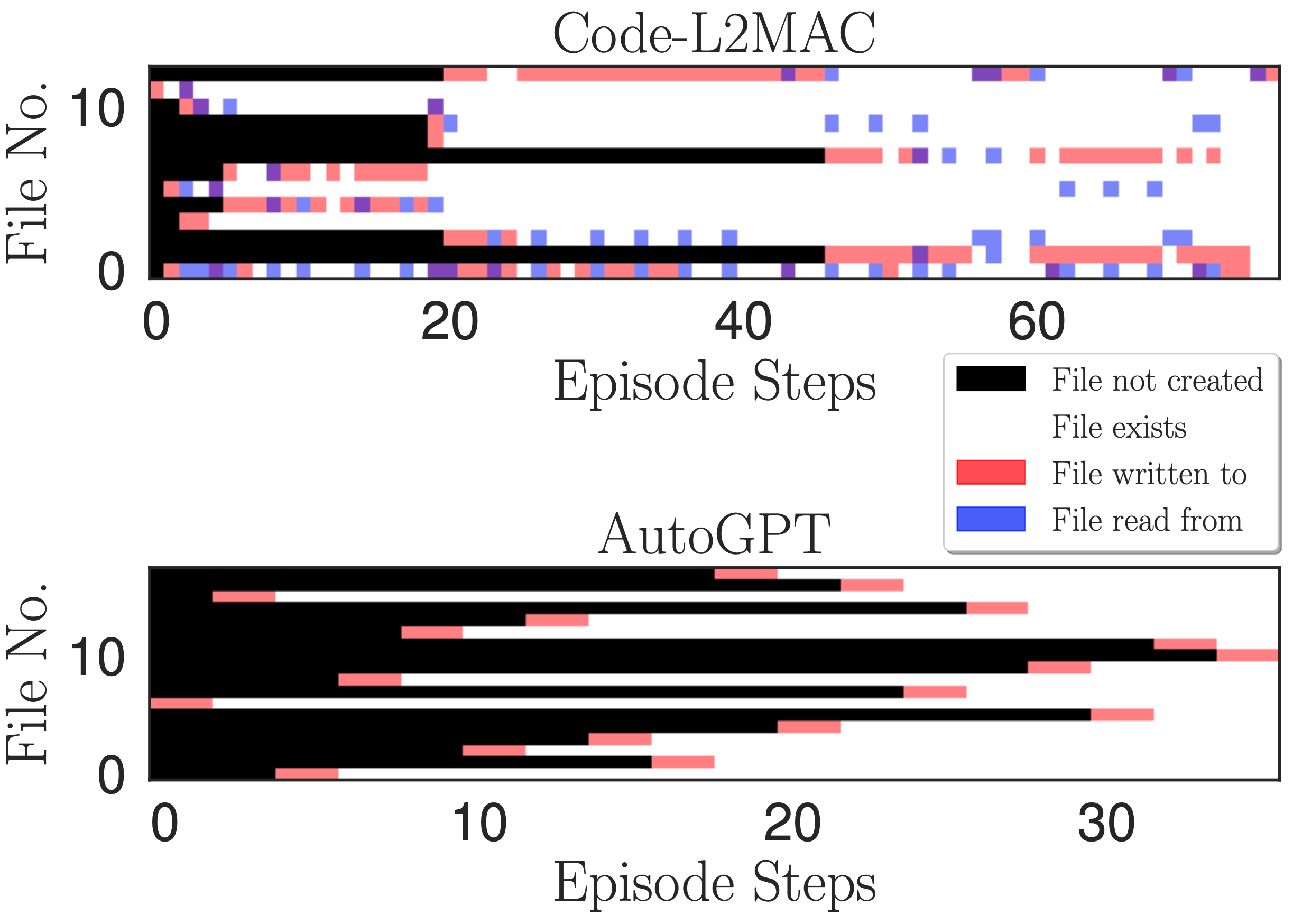
Heatmap of file access. Indicating reading, writing, and when files are created at each write operation step during one episode for the Online Chat App task.
We wish to understand, during the operation of executing a task instruction, if L2MAC can understand the existing generated code files within the codebase---which could have been created many instructions ago, and through its understanding, create new files that interrelate with the existing files, and most importantly update existing code files as new features are implemented. To derive insight, we plot a heatmap of the reading, writing, and when files are created at each write operation step during one episode in the above figure. We observe that L2MAC has an understanding of the existing generated code that allows it to update existing code files, even those originally created many instruction steps ago, and can view the files when it is not certain and update the files through writing to the files. In contrast, AutoGPT often only writes to files once, when initially creating them, and can only update files that it knows about that are retained within its current context window. Although it also has a read file tool, it often forgets about the files that it created many iterations ago due to its context window handling approach of summarizing the oldest dialog messages in its context window, i.e., a continual lossy compression of the previous progress made during operation of completing the task.
Can L2MAC check the generated output and error correct?
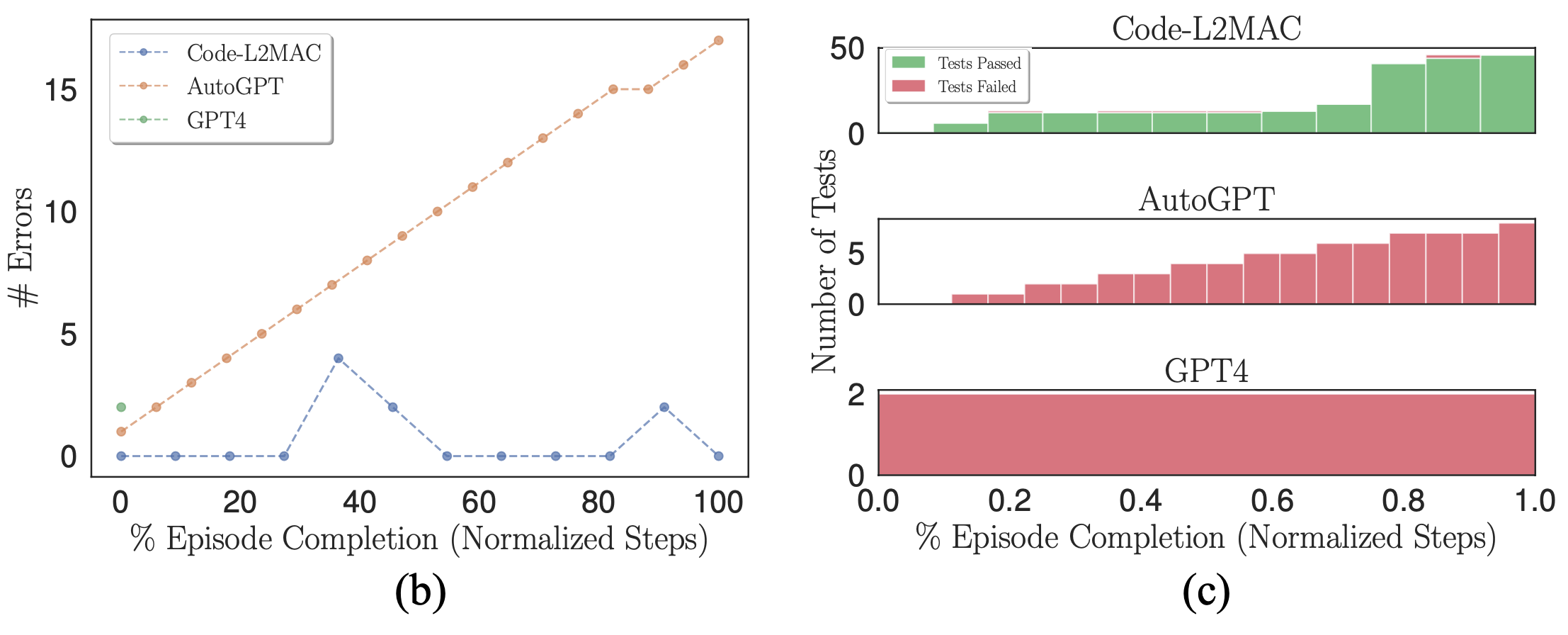
(b) Number of syntactical errors within the codebase. (c) Stacked histograms of passing and failing self-generated unit tests.
When using a probabilistic model (LLM) as a generator to output code, errors can naturally occur in its outputs. Therefore, we wish to verify if, when errors do appear, the respective benchmark methods can error-correct the codebase. We plot the number of syntactical errors in the codebase during a run where errors are made in the above figure (b). We observe that L2MAC can correctly error correct the previously generated codebase that has errors contained within, which could arise from syntactical errors from the last file written or other files that depend on the most recent file written, which now contain errors. It does this by being presented with the error output when it does arise and modifying the codebase to resolve the error whilst still completing the current instruction. In contrast, AutoGPT cannot detect when an error in the codebase has been made and continues operating, which can compound the number of errors forming within the codebase.
Moreover, L2MAC generates unit tests alongside the functional code and uses these as an error checker to inspect the functionalities of the codebase as it is generated and can use these errors to fix the codebase to pass unit tests that now fail after updating part of an existing file. We show this in the above figure (c) and observe that AutoGPT, whilst prompted to also write unit tests for all code generated, is unable to use these tests as an integrity error check, which could be compounded by the observation that AutoGPT forgets which files it has previously created and hence unable to modify the existing forgotten code files as new modifications are made, leading to incompatible code files.
Summary
We present L2MAC, the first LLM-based general-purpose stored-program computer framework that effectively and scalably augments LLMs with a memory store for long output generation tasks where this was not previously successfully achieved. Specifically, L2MAC, when applied for long code generation tasks, surpasses existing solutions—and is an immensely useful tool for rapid development. We welcome contributions and encourage you to use and cite the project.