Neural Ordinary Differential Equations model dynamical systems with ODEs learned by neural networks. However, ODEs are fundamentally inadequate to model systems with long-range dependencies or discontinuities, which are common in engineering and biological systems. Broader classes of differential equations (DE) have been proposed as remedies, including delay differential equations and integro-differential equations. Furthermore, Neural ODE suffers from numerical instability when modelling stiff ODEs and ODEs with piecewise forcing functions. In this work, we propose Neural Laplace, a unifying framework for learning diverse classes of DEs including all the aforementioned ones. Instead of modelling the dynamics in the time domain, we model it in the Laplace domain, where the history-dependencies and discontinuities in time can be represented as summations of complex exponentials. To make learning more efficient, we use the geometrical stereographic map of a Riemann sphere to induce more smoothness in the Laplace domain. In the experiments, Neural Laplace shows superior performance in modelling and extrapolating the trajectories of diverse classes of DEs, including the ones with complex history dependency and abrupt changes.
In International Conference on Machine Learning | Long Oral, top 2% of papers
Long Oral Presentation
Paper Key Figures
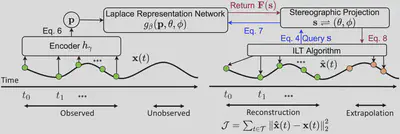
Comparison between Neural Laplace and Neural ODE’s modeling approaches. Neural Laplace models DE solutions in the Laplace domain $F(s)$ and uses the inverse Laplace transform to generate the time solution $x(t)$ at any time in the time domain. The Laplace representation $F(s)$ can represent broader classes of DE solutions than that of an ODE. Neural Laplace further uses a stereographic projection to remove the singularities $\infty$ of $F(s)$, forming a continuous and compact domain that improves learning. In contrast, Neural ODE models $\dot{x}$ in the time domain using a stepwise numerical ODE solver to generate the time solution.
Block diagram of Neural Laplace. The query points s are given by the ILT algorithm based on the time points to reconstruct or extrapolate. The gradients can be back-propagated through the ILT algorithm and stereographic projection to train networks $h_\gamma$ and $g_\beta$.
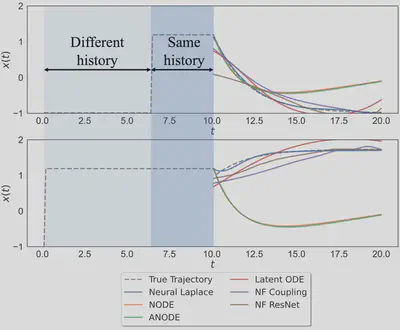
Two test trajectories of the Mackey Glass DDE, with benchmarks, illustrating examples where the distant history impact the future trajectory, even though momentarily they may have the same history for short times, $6 \leq t \leq 10$.
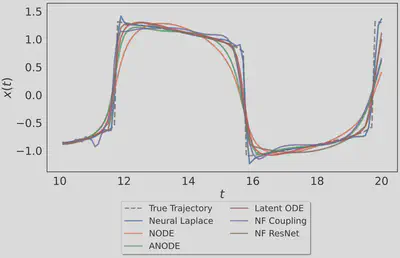
Test extrapolation plots with benchmarks for Stiff Van der Pol Oscillator DE. Neural Laplace is able to correctly extrapolate the DE dynamics.
 ICML Long Oral
ICML Long Oral