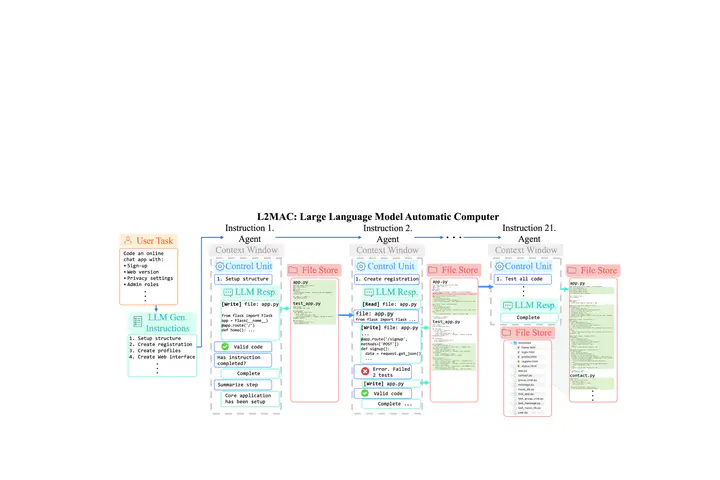
Transformer-based large language models (LLMs) are constrained by the fixed context window of the underlying transformer architecture, hindering their ability to produce long and coherent outputs. Memory-augmented LLMs are a promising solution, but current approaches cannot handle long output generation tasks since they (1) only focus on reading memory and reduce its evolution to the concatenation of new memories or (2) use very specialized memories that cannot adapt to other domains. This paper presents L2MAC, the first practical LLM-based general-purpose stored-program automatic computer (von Neumann architecture) framework, an LLM-based multi-agent system, for long and consistent output generation. Its memory has two components: the instruction registry, which is populated with a prompt program to solve the user-given task, and a file store, which will contain the final and intermediate outputs. Each instruction in turn is executed by a separate LLM agent, whose context is managed by a control unit capable of precise memory reading and writing to ensure effective interaction with the entire file store. These components enable L2MAC to generate extensive outputs, bypassing the constraints of the finite context window while producing outputs that fulfill a complex user-specified task. We empirically demonstrate that L2MAC achieves state-of-the-art performance in generating large codebases for system design tasks, significantly outperforming other coding methods in implementing the detailed user-specified task; we show that L2MAC works for general-purpose extensive text-based tasks, such as writing an entire book; and we provide valuable insights into L2MAC’s performance improvement over existing methods.
International Conference on Learning Representations (ICLR 2024)
Paper Key Figure
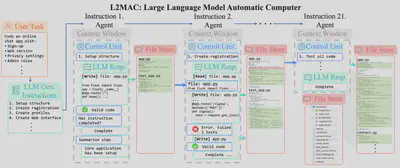
L2MAC Overview. Code-L2MAC is an instantiation of the LLM automatic computer (L2MAC) framework, an LLM-based multi-agent system, here for extensive code generation. First, it breaks down the user task into sequential instructions $\mathcal{I}$. The Control Unit (CU) manages the LLM’s context window for each instruction (agent) and interacts with the external memory file store through read, write, and evaluate tools. It identifies and reads relevant files from the memory to generate or update files per instruction (P2). This ensures proper conditioning of existing files without losing vital context (P1). Automatic checks evaluate the LLM’s outputs for correctness and completion (P3), with iterative error corrections involving both code syntactical checks of the code and running self-generated unit tests to check desired functionality. Overall, this produces a complete large codebase that fulfills the detailed user task in the file store.
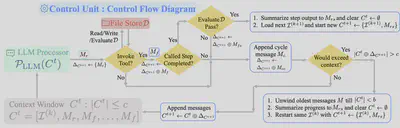
Control Unit—control flow diagram for one dialog turn $t$. Here this executes one current instruction $\mathcal{I}^{(k)}$. It starts by loading the first instruction into the context window $C^0\leftarrow {\mathcal{I}^{(0)}}$ and iterates it automatically until all instructions in $\mathcal{I}$ have been executed. First, $C^t$ is processed by the LLM Processor $\mathcal{P}(C^t)$ to output $M_r$. The CU stores this in a buffer $\Delta_{C^{t+1}} \leftarrow {M_r}$, and checks if $M_r$ has called a tool, and if so, it executes the tool with the specified input in $M_r$, which includes reading, writing and evaluating $\mathcal{E}(D)$ the file store $\mathcal{D}$—outputting $M_f$, which is appended to the buffer $\Delta_{C^{t+1}}$. The CU performs additional control flow, for checking if an instruction has been completed, continuing an instruction beyond the context window (P1), and continuing executing the current instruction.