Abstract
The control of continuous-time environments while actively deciding when to take costly observations in time is a crucial yet unexplored problem, particularly relevant to real-world scenarios such as medicine, low-power systems, and resource management. Existing approaches either rely on continuous-time control methods that take regular, expensive observations in time or discrete-time control with costly observation methods, which are inapplicable to continuous-time settings due to the compounding discretization errors introduced by time discretization. In this work, we are the first to formalize the continuous-time control problem with costly observations. Our key theoretical contribution shows that observing at regular time intervals is not optimal in certain environments, while irregular observation policies yield higher expected utility. This perspective paves the way for the development of novel methods that can take irregular observations in continuous-time control with costly observations. We empirically validate our theoretical findings in various continuous-time environments, including a cancer simulation, by constructing a simple initial method to solve this new problem, with a heuristic threshold on the variance of reward rollouts in an offline continuous-time model-based model predictive control (MPC) planner. Although determining the optimal method remains an open problem, our work offers valuable insights and understanding of this unique problem, laying the foundation for future research in this area.
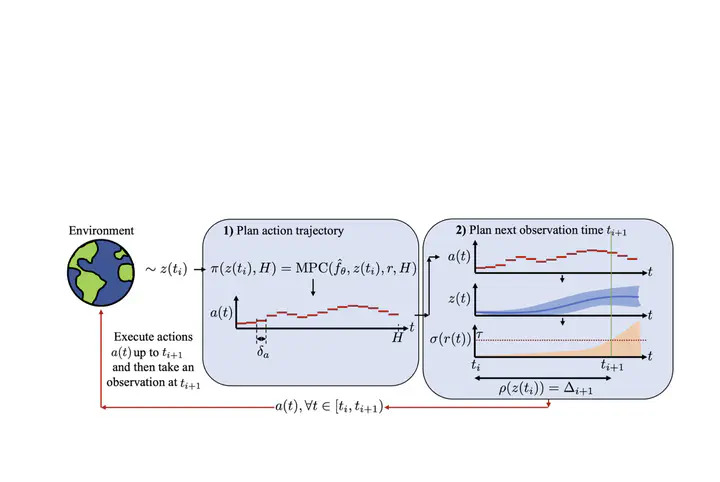
Paper Key Figure