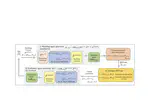
High-frequency control in continuous action and state spaces is essential for practical applications in the physical world. Directly applying end-to-end reinforcement learning to high-frequency control tasks struggles with assigning credit to actions across long temporal horizons, compounded by the difficulty of efficient exploration. The alternative, learning low-frequency policies that guide higher-frequency controllers (e.g., proportional-derivative (PD) controllers), can result in a limited total expressiveness of the combined control system, hindering overall performance. We introduce EvoControl, a novel bi-level policy learning framework for learning both a slow high-level policy (using PPO) and a fast low-level policy (using Evolution Strategies) for solving continuous control tasks. Learning with Evolution Strategies for the lower-policy allows robust learning for long horizons that crucially arise when operating at higher frequencies. This enables EvoControl to learn to control interactions at a high frequency, benefitting from more efficient exploration and credit assignment than direct high-frequency torque control without the need to hand-tune PD parameters. We empirically demonstrate that EvoControl can achieve a higher evaluation reward for continuous-control tasks compared to existing approaches, specifically excelling in tasks where high-frequency control is needed, such as those requiring safety-critical fast reactions.
Samuel Holt, Todor Davchev, Dhruva Tirumala, Ben Moran, Atil Iscen, Antoine Laurens, Yixin Lin, Erik Frey, Markus Wulfmeier, Francesco Romano, Nicolas Heess