Biography
I am a Research Scientist at Google DeepMind working on LLM agents and their learning dynamics, with a particular focus on reinforcement learning (RL), and a broader goal of helping build universal AI assistants—systems that can understand and remember context, use tools, act on users’ behalf across devices, and, in the longer term, help accelerate scientific discovery.
Before joining Google DeepMind full-time, I completed a PhD in machine learning at the University of Cambridge, supervised by Prof. Mihaela van der Schaar FRS in the Machine Learning and Artificial Intelligence group. My research focused on reinforcement learning for and with large language models: memory-augmented agents, tool use, scalable long-context generation, and automating parts of the scientific pipeline. My first-author work has appeared at NeurIPS, ICLR, ICML, AISTATS, and RSS, including multiple spotlights and a long oral. Earlier, I also worked with Google DeepMind on hierarchical RL and the MuJoCo Playground project.
Some recurring themes in my work are:
- LLM agents with memory, tools, and lookahead – agents that maintain verifiable “atomic facts”, call tools, and perform depth-limited search to act in long-horizon, interactive environments.
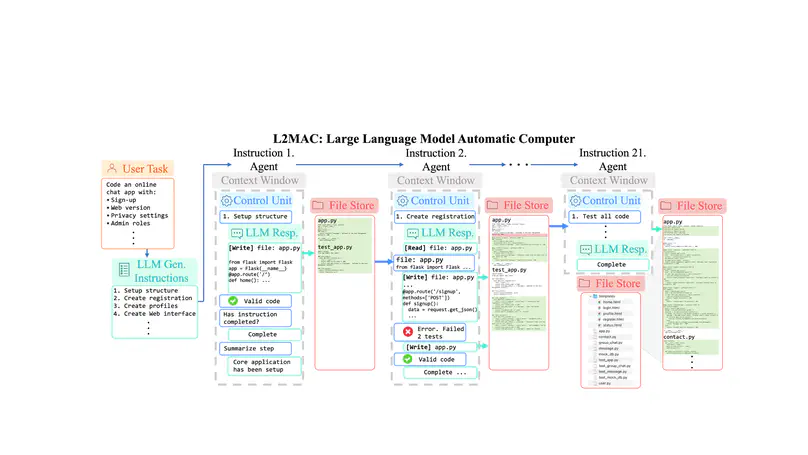
- Unbounded code and content generation – systems that combine external memory, execution feedback, tool use, and multi-agent coordination to produce large, coherent artefacts (e.g., codebases, books).
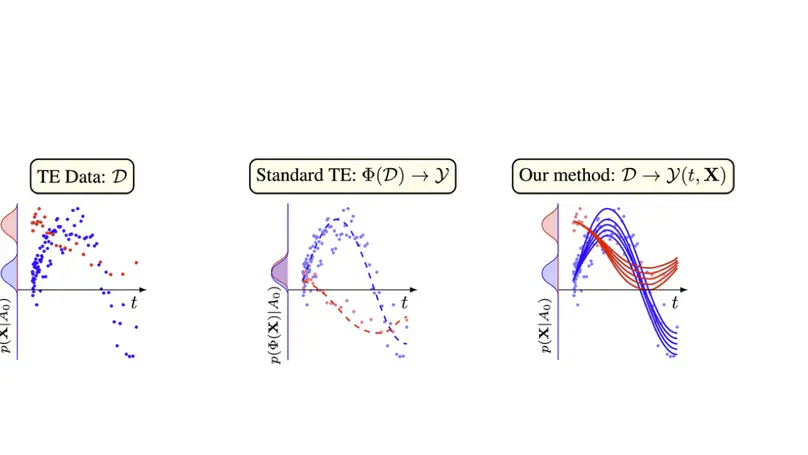
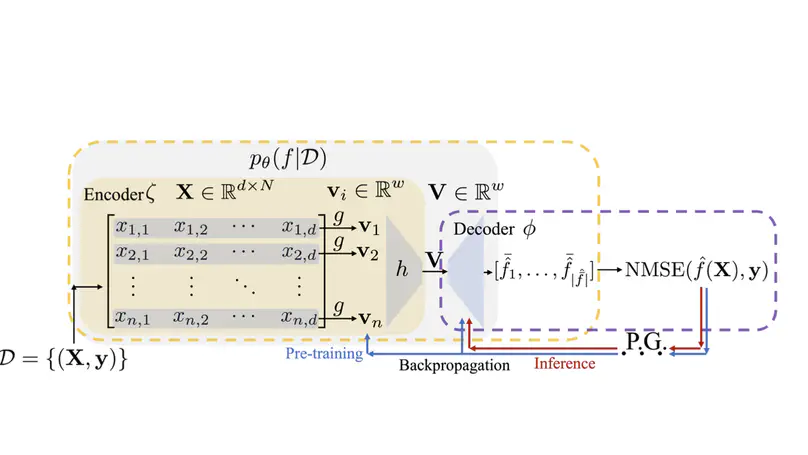
- Agents optimising algorithms and simulators for science – LLM/code agents that propose and refine preference-optimisation algorithms, architectures, symbolic representations, and generative simulations for downstream tasks.
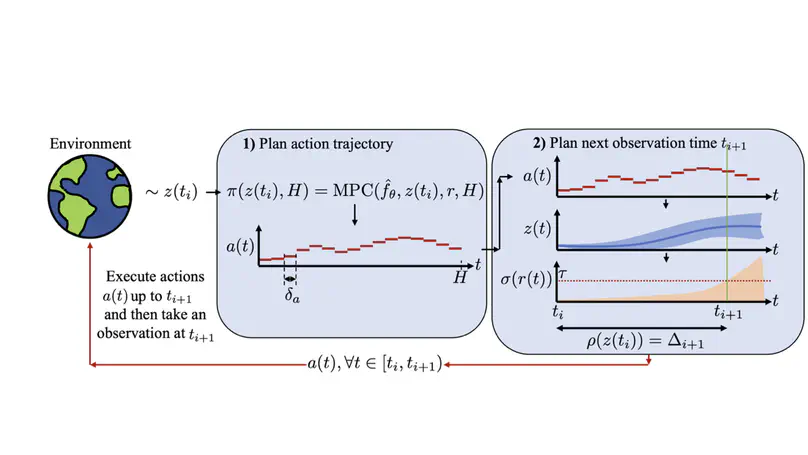
- RL at inference time – using RL and search during inference to adapt language model behaviour, improving efficiency and output quality.
I’m a team-first researcher who enjoys pairing ideas with rigorous prototypes, evaluation, and publications, always with an eye toward scalable, self-improving agentic systems that move us closer to universal AI assistants.
- LLM agents (memory, tools, planning)
- Reinforcement learning (incl. RL at inference time)
- Universal AI assistants & agentic systems
- Long-context & large-scale code/content generation
- Automated discovery & scientific applications
PhD in Machine Learning, 2021 - 2025
University of Cambridge
MEng in Engineering Science, 2013 - 2017
University of Oxford
Publications
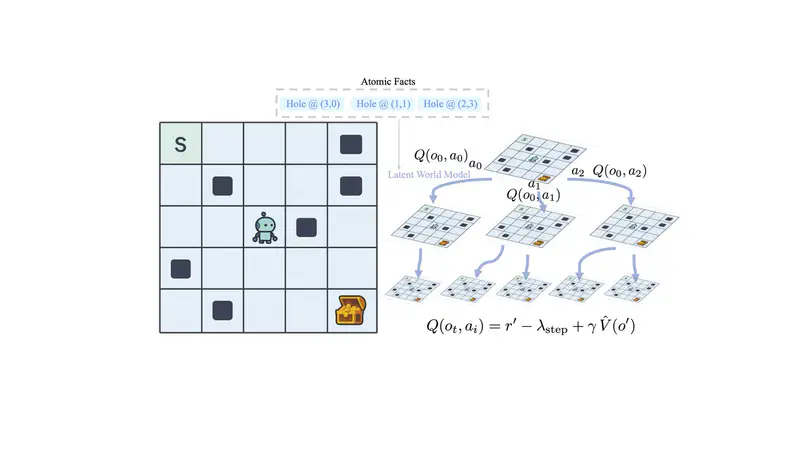
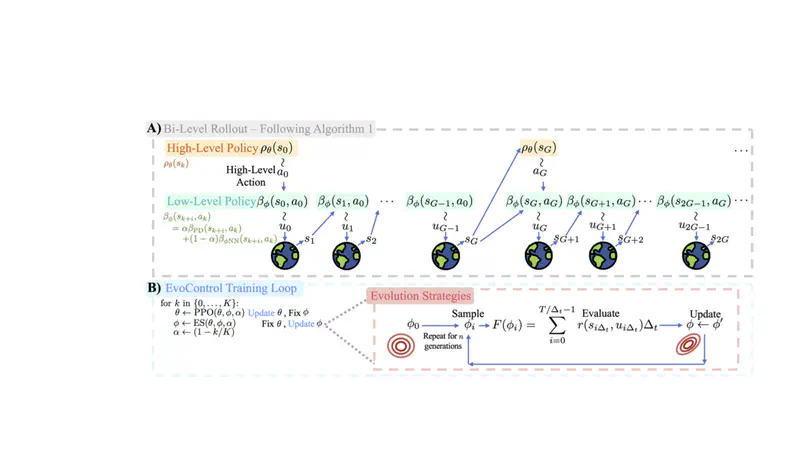

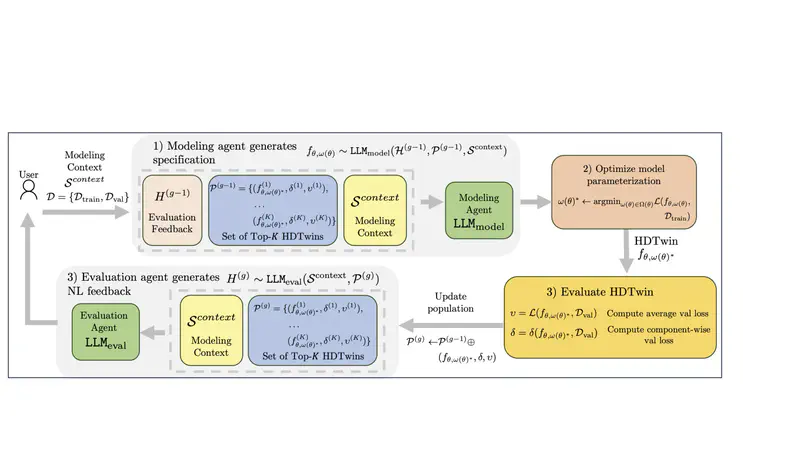

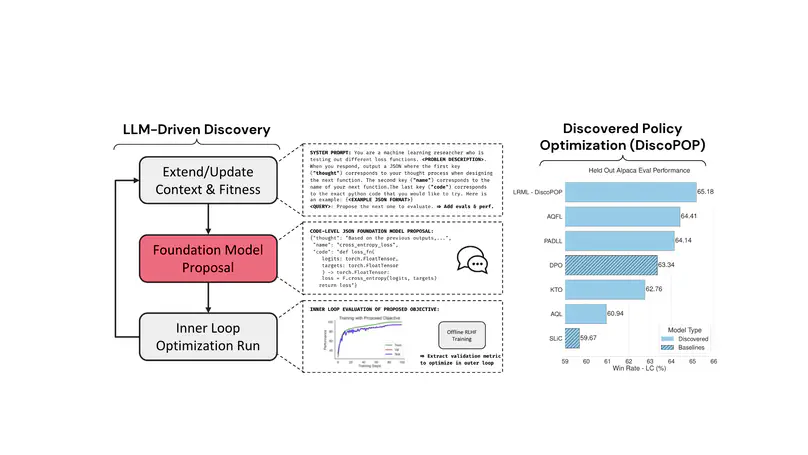

Academic Service & Volunteering
- Conference Reviewer: ICML 2022, AISTATS 2023, NeurIPS 2023, ICLR 2024, ICML 2024, Nature Machine Intelligence 2024, NeurIPS 2024, NeurIPS 2025, AISTATs 2025, ICML 2025.
- Workshop Reviewer: ICLR 2023 AI4ABM, NeurIPS 2022 & 2023 SyntheticData4ML.
Sole Author and Teacher for Machine Learning and Deep Learning Course.
- Authored ML video course, nine chapters, 10.5 video hours covering theory and code examples of ML and Deep Learning in Supervised Learning, Unsupervised Learning and Reinforcement Learning.
- Covered Deep Learning for Computer Vision (GANs, VAEs, Style Transfer, Semantic Segmentation, CNNs), NLP, RNNs, Sequence to Sequence, Transformers, Time Series forecasting and Deep Reinforcement Learning (MDPs, Q-Learning, Value and Policy based methods, Multi-armed bandits, Inverse RL, Model-based RL, i.e. Alpha Zero).
- All teaching Jupyter notebooks are online. Also contributed to open source ML frameworks, TensorFlow Core, OpenAI libraries and ML Wikipedia pages.
Skills
Python, Javascript, Typescript, RUST, MATLAB, Bash, SQL, C, C++
Jax, TensorFlow, PyTorch, Keras, NumPy, SciPy, Pandas, Asyncio, Nltk, Jupyter, PyTest
git, Linux, LaTeX, Google Cloud Platform, Amazon Web Services, Docker, GitLab CI
Recent Publications
Contact
- sih31(at)cam.ac.uk
- Centre for Mathematical Sciences, Wilberforce Rd, Cambridge, CB3 0WA